In an earlier post, I documented the local and remote memory latencies for the SunBlade X6420 compute nodes in the TACC Ranger supercomputer, using AMD Opteron “Barcelona” (model 8356) processors running at 2.3 GHz.
Similar latency tests were run on other systems based on AMD Opteron processors in the TACC “Discovery” benchmarking cluster. The systems reported here include
- 2-socket node with AMD Opteron “Shanghai” processors (model 2389, quad-core, revision C2, 2.9 GHz)
- 2-socket node with AMD Opteron “Istanbul” processors (model 2435, six-core, revision D0, 2.6 GHz)
- 4-socket node with AMD Opteron “Istanbul” processors (model 8435, six-core, revision D0, 2.6 GHz)
- 4-socket node with AMD Opteron “Magny-Cours” processors (model 6174, twelve-core, revision D1, 2.2 GHz)
Compared to the previous results with the AMD Opteron “Barcelona” processors on the TACC Ranger system, the “Shanghai” and “Istanbul” processors have a more advanced memory controller prefetcher, and the “Istanbul” processor also supports “HT Assist”, which allocates a portion of the L3 cache to serve as a “snoop filter” in 4-socket configurations. The “Magny-Cours” processor uses 2 “Istanbul” die in a single package.
Note that for the “Barcelona” processors, the hardware prefetcher in the memory controller did not perform cache coherence “snoops” — it just loaded data from memory into a buffer. When a core subsequently issued a load for that address, missing in the L3 cache initiated a coherence snoop. In both 2-socket and 4-socket systems, this snoop took longer than obtaining the data from DRAM, so the memory prefetcher had no impact on the effective latency seen by a processor core. “Shanghai” and later Opteron processors include a coherent prefetcher, so prefetched lines could be loaded with lower effective latency. This difference means that latency testing on “Shanghai” and later processors needs to be slightly more sophisticated to prevent memory controller prefetching from biasing the latency measurements. In practice, using a pointer-chasing code with a stride of 512 Bytes was sufficient to avoid hardware prefetch in “Shanghai”, “Istanbul”, and “Magny-Cours”.
Results for 2-socket systems
| Processor | cores/package | Frequency | Family | Revision | Code Name | Local Latency (ns) | Remote Latency (ns) |
|---|---|---|---|---|---|---|---|
| Opteron 2222 | 2 | 3000 | 0Fh | 60 | 95 | ||
| Opteron 2356 | 4 | 2300 | 10h | B3 | Barcelona | 85 | |
| Opteron 2389 | 4 | 2900 | 10h | C2 | Shanghai | 73 | |
| Opteron 2435 | 6 | 2600 | 10h | D0 | Istanbul | 78 | |
| Opteron 6174 | 12 | 2200 | 10h | D1 | Magny-Cours |
Notes for 2-socket results:
- The values for the Opteron 2222 are from memory, but should be fairly accurate.
- The local latency value for the Opteron 2356 is from memory, but should be in the right ballpark. The latency is higher than the earlier processors because of the lower core frequency, the lower “Northbridge” frequency, the presence of an L3 cache, and the asynchronous clock boundary between the core(s) and the Northbridge.
- The script used for the Opteron 2389 (“Shanghai”) did not correctly bind the threads, so no remote latency data was collected.
- The script used for the Opteron 2435 (“Istanbul”) did not correctly bind the threads, so no remote latency data was collected.
- The Opteron 6174 was not tested in the 2-socket configuration.
Results for 4-socket systems
| Processor | Frequency | Family | Revision | Code Name | Local Latency (ns) | Remote Latency (ns) | NOTES | 1-hop median Latency (ns) | 2-hop median Latency (ns) |
|---|---|---|---|---|---|---|---|---|---|
| Opteron 8222 | 3000 | 0Fh | 90 | ||||||
| Opteron 8356 | 2300 | 10h | B3 | Barcelona | 100/133 | 122-146 | 1,2 | ||
| Opteron 8389 | 2900 | 10h | C2 | Shanghai | |||||
| Opteron 8435 | 2600 | 10h | D0 | Istanbul | 56 | 118 | 3,4 | ||
| Opteron 6174 | 2200 | 10h | D1 | Magny-Cours | 56 | 121-179 | 5 | 124 | 179 |
Notes for 4-socket results:
- On the 4-socket Opteron 8356 (“Barcelona”) system, 2 of the 4 sockets have a local latency of 100ns, while the other 2 have a local latency of 133ns. This is due to the asymmetric/anisotropic HyperTransport interconnect, in which only 2 of sockets have direct connections to all other sockets, while the other 2 sockets require two hops to reach one of the remote sockets.
- On the 4-socket Opteron 8356 (“Barcelona”) system, the asymmetric/anisotropic HyperTransport interconnect gives rise to several different latencies for various combinations of requestor and target socket. This is discussed in more detail at AMD “Barcelona” Memory Latency.
- Starting with “Istanbul”, 4-socket systems have lower local latency than 2-sockets systems because “HyperTransport Assist” (a probe filter) is activated. Enabling this feature reduces the L3 cache size from 6MiB to 5MiB, but enables the processor to avoid sending probes to the other chips in many cases (including this one).
- On the 4-socket Opteron 8435 (“Istanbul”) system, the scripts I ran had an error causing them to only measure local latency and remote latency on 1 of the 3 remote sockets. Based on other system results, it looks like the remote value was measured for a single “hop”, with no values available for the 2-hop case.
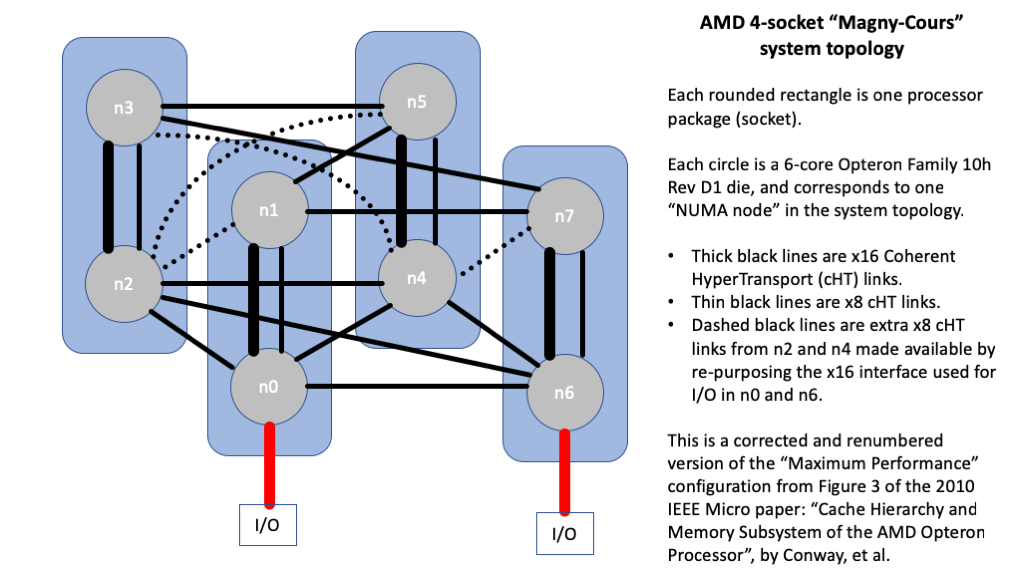
- On the 4-socket Opteron 6140 (“Magny-Cours”) system, each package has 2 die, each constituting a separate NUMA node. The HyperTransport interconnect is asymmetric/anisotropic, with 2 die having direct links to 6 other die (with 1 die requiring 2 hops), and the other 6 die having direct links to 4 other die (with 3 die requiring 2 hops). The average latency for globally uniform accesses (local and remote) is 133ns, while the average latency for uniformly distributed remote accesses is 144ns.
Comments
This disappointingly incomplete dataset still shows a few important features….
- Local latency is not improving, and shows occasional degradations
- Processor frequencies are not increasing.
- DRAM latencies are essentially unchanged over this period — about 15 ns for DRAM page hits, 30 ns for DRAM pages misses, 45 ns for DRAM page conflicts, and 60 ns for DRAM bank cycle time. The latency benchmark is configured to allow open page hits for the majority of accesses, but these results did not include instrumentation of the DRAM open page hit rate.
- Many design changes act to increase memory latency.
- Major factors include the increased number of cores per chip, the addition of a shared L3 cache, the increase in the number of die per package, and the addition of a separate clock frequency domain for the Northbridge.
- There have been no architectural changes to move away from the transparent, “flat” shared-memory paradigm.
- Instead, overcoming these latency adders required the introduction of “probe filters” – a useful feature, but one that significantly complicates the implementation, uses 1/6th of the L3 cache, and significantly complicates performance analysis.
- Remote latency is getting slowly worse
- This is primarily due to the addition of the L3 cache, the increase in the number of cores, and the increase in the number of die per package.
Magny-Cours Topology
The pointer-chasing latency code was run for all 64 combinations of data binding (NUMA nodes 0..7) and thread binding (1 core chosen from each of NUMA nodes 0..7). It was not initially clear which topology was used in the system under test, but the observed latency pattern showed very clearly that 2 NUMA nodes had 6 1-hop neighbors, while the other 6 NUMA nodes had only 4 1-hop neighbors. This property is also shown by the “Max Perf” configuration from Figure 3(c) of the 2010 IEEE Micro paper “Cache Hierarchy and Memory Subsystem of the AMD Opteron Processor” by Conway, et al. (which I highly recommend for its discussion of the cache coherence protocol and probe filter). The figure below corrects an error from the figure in the paper (which is missing the x16 link between the upper and lower chips in the package on the left), and renumbers the die so that they correspond to the NUMA nodes of the system I was testing.
The latency values are quite easy to understand: all the local values are the same, all the 1-hop values are almost the same, and all the 2-hop values are the same. (The 1-hop values that are within the same package are about 3.3ns faster than the 1-hop values between packages, but this is a difference of less than 3%, so it will not impact “real-world” performance.)
The bandwidth patterns are much less pretty, but that is a much longer topic for another day….