We can compare the distribution of a numeric variable across the groups of a categorical variable using a grouped histogram. Creating a grouped histogram is essentially making an individual histogram separately for each group and putting them on the same set of axes and using the same bin width. For more information, see our page on histograms).
Keep in mind that you’ll need to use identical scales on your axes and bin widths so that you can compare values across groups. When comparing the distribution of your numeric variable across multiple groups, consider the following:
- Shape – how do the shapes of the distributions compare? Is one group’s data skewed and the other not? Do all the groups have a similar number of modes?
- Center – do the groups have similar average values? We can eyeball the center of each distribution by the shape and location of the mode.
- Spread – do all the groups have similar range of values? Does one group appear to have more variation than another?
- Unique features – do any of the groups contain outliers?
When comparing center and spread of multiple distributions, be sure to use the same measures. Which descriptive statistics you use depends on the shapes of the distributions. If all distributions are symmetric, then you can use the mean and standard deviation to describe their center and spread. However, if at least one group has a skewed distribution, then you need to use the median and IQR or 5-number summary to describe all groups.
Example:
Group A Group B
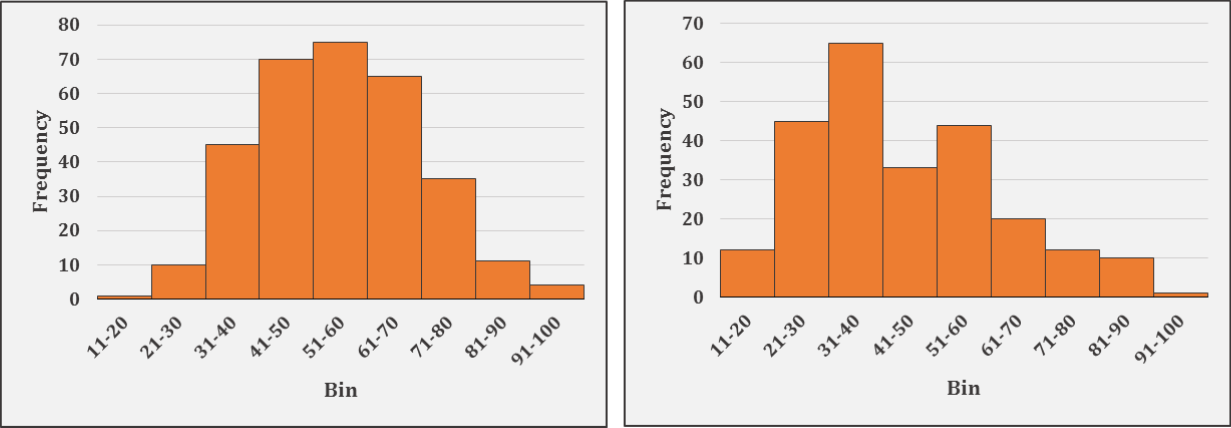
Group A’s distribution is symmetric and Group B’s distribution is right-skewed. The median of Group A, 55, is greater than the median Group B, 40. However, both groups have a similar spread, with the interquartile range (IQR) for Group A equal to 23, and for Group B equal to 25. Neither distribution has any outliers.
Refer back to the histogram page for creating single histograms.
Example 1: Creating grouped histograms in R
This example compares the distribution of BMI across patients with and without diabetes.
Dataset used in videos
R script file used in video