
Published on Nov 1 2024
Written by Sunny Sanyal1
Joint work with Ravid Shwartz-Ziv2, Alex Dimakis1 and Sujay Sanghavi1
UT Austin1 and Newyork University2
Paper: https://arxiv.org/abs/2404.08634
Code: https://github.com/sanyalsunny111/LLM-Inheritune
Slides: https://docs.google.com/presentation/d/1RIdDTbIR14P9cH75w41AO5LIWlLeMx7ISpqjvjtpgis/edit?usp=sharing
TL;DR: Here we observe that in decoder-style LLMs (built with vanilla transformer blocks and multi-headed attention), many attention matrices in the deeper layers degenerate to rank-1. A significant number of these rank-1 matrices are essentially single-column attention matrices. To address this, we proposed a solution where we remove the deeper layers with degenerated attention and progressively grow the model in a stacking-like manner. This method allowed us to train smaller, yet equally performant language models, compared to their larger, less efficient counterparts.
Attention Matrices Degenerates to Single Column in Pre-trained Decoder-Style GPT2 Models
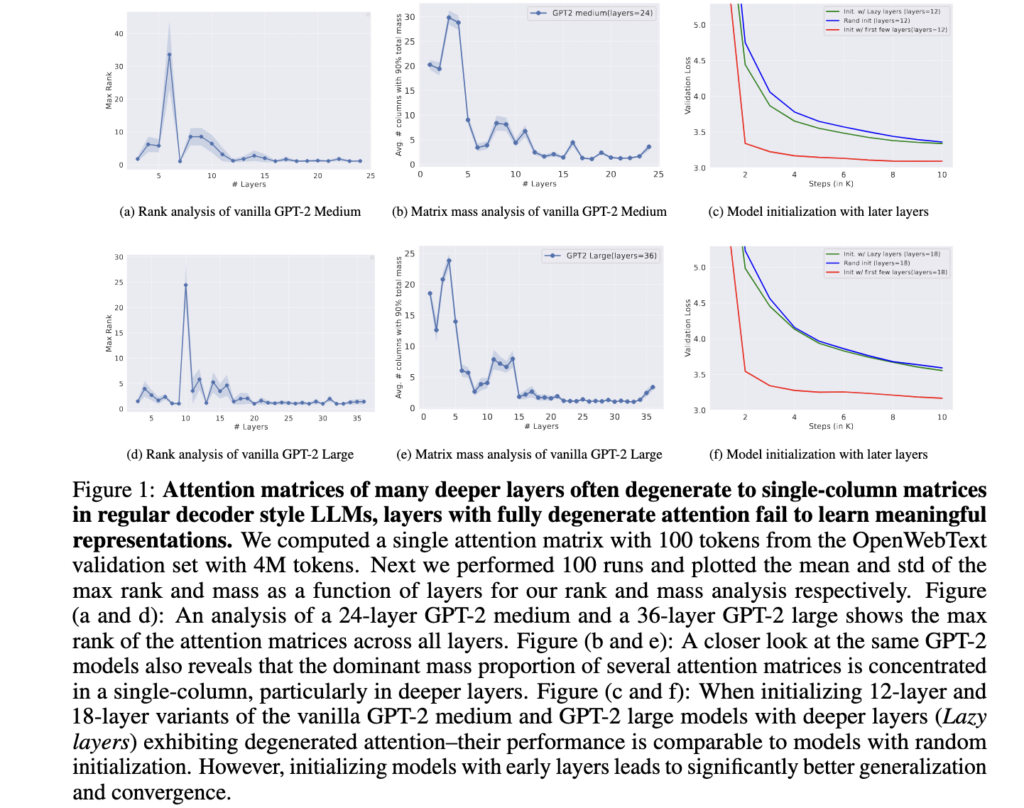


We computed the layerwise rank and mass of all the attention matrices for all the attention heads in both GPT2 medium and large as shown in Fig.1. It is quite evident that attention matrices of many deeper layers are only focusing on a single column. We refer to this phenomenon as attention degeneration.
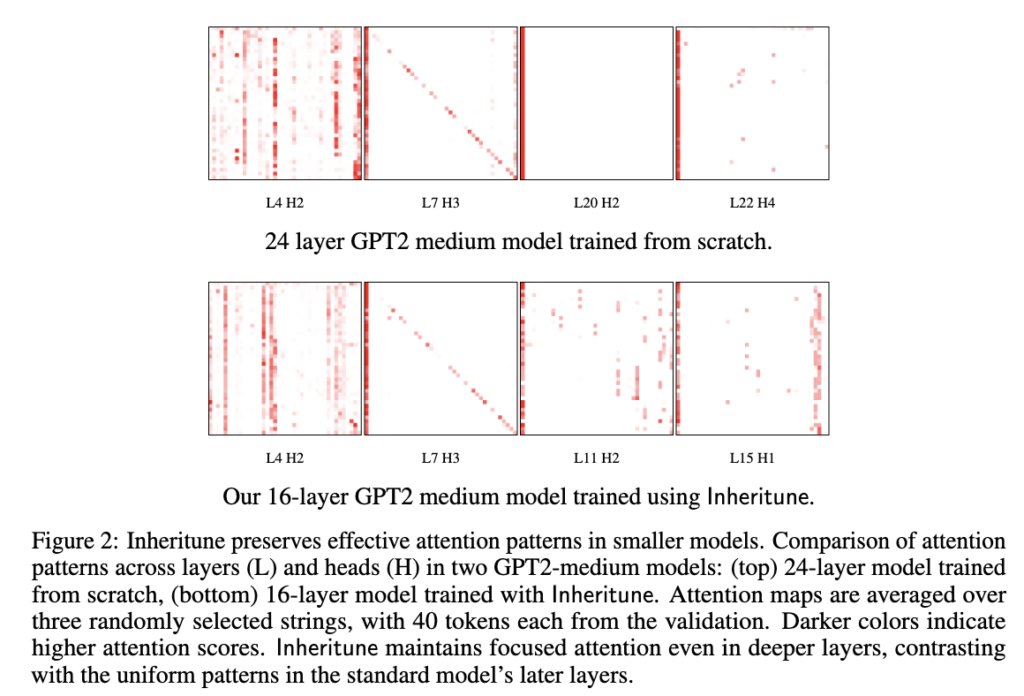
Now let’s visualize some of the attention matrices of a pre-trained GPT2-medium model(refer Fig.2).
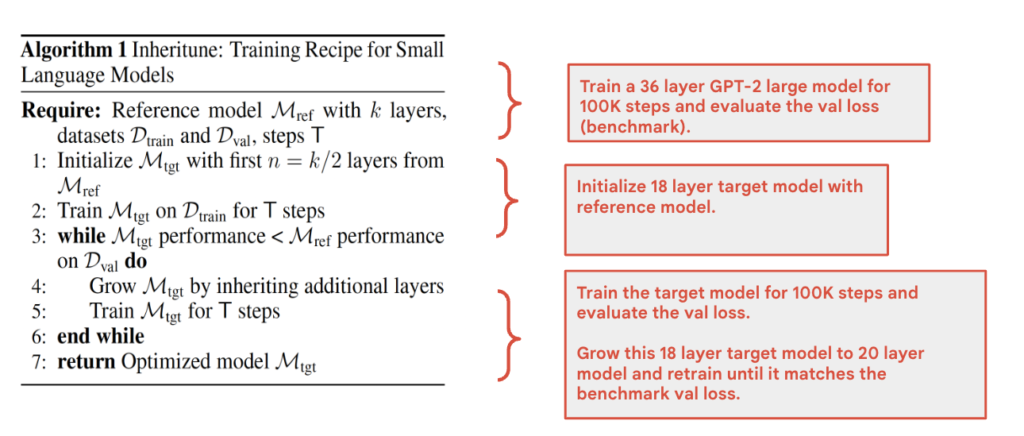
Inheritune: Cutoff Degenerated Layers and Stagewise Retrain
We explain our method Inheritune with an example of a 36 layer GPT-2 large model.
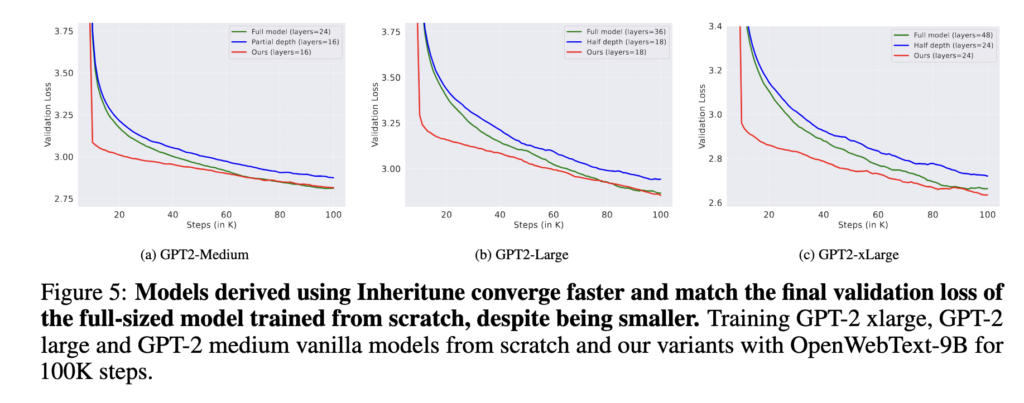
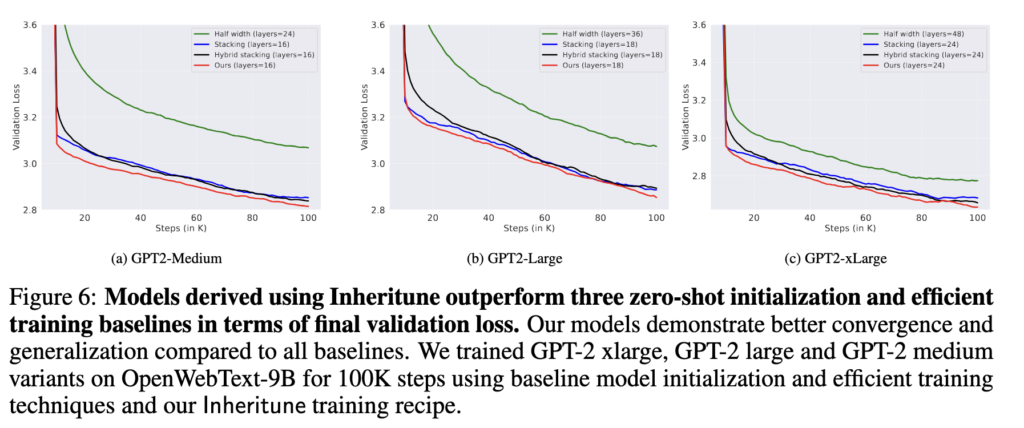
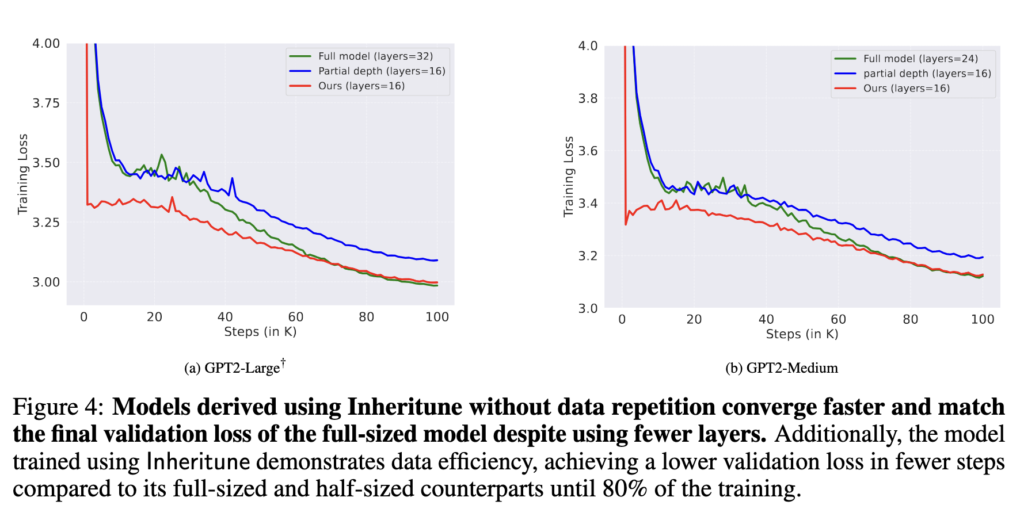
Main Results
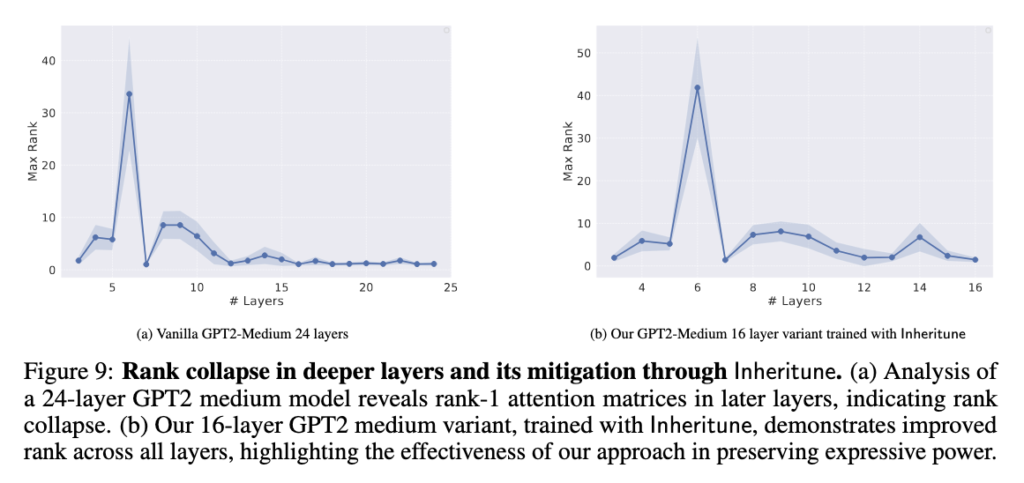
Turns out we can train much smaller models once we address the attention degeneration issue (refer Fig.9 and other results below).
Further Reading
Paper 1: https://arxiv.org/abs/2406.04267
Paper 2: https://proceedings.mlr.press/v119/bhojanapalli20a.html
Paper 3: https://arxiv.org/abs/2404.07647
Bibtex
@article{sanyal2024inheritunetrainingsmallerattentive,
title={Inheritune: Training Smaller Yet More Attentive Language Models},
author={Sunny Sanyal and Ravid Shwartz-Ziv and Alexandros G. Dimakis and Sujay Sanghavi},
year={2024},
eprint={2404.08634},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2404.08634},
}