Part of our campus AI journey is to design and deploy AI agents that can utilize key information from exisiting websites across campus. These agents may replace the sites, reducing technical bloat and information drift. While doing so, an unexpected benefit has emerged, one that speaks volumes about the evolving relationship between technology and content strategy on a highly decentralized campus.
When we first set out to build these agents, we did what most teams do, we pointed them at our sites or their underlying data, ingested the knowledge, tested retrieval, and began crafting conversations. But something interesting happened when we put these agents to work. People have started asking for things we couldn’t give them.
In short, the agents began surfacing questions we hadn’t anticipated; questions students, faculty, staff, and prospective Longhorns are likely asking every day. And, just as importantly, they showed us where our data and content fell short.
They have become mirrors, reflecting the structure, and the fragmentation, of our institutional knowledge. The things they cannot answer point directly to gaps in the content architecture: outdated FAQs, scattered documentation, siloed policy pages, and even buried gems of information lost in PDF archives or legacy web systems. It’s not that the information doesn’t exist. It’s that it’s too hard to find, inconsistently written, or lacks the context necessary to form a coherent response. We are sure the agent isn’t making mistakes per say, it tells us what it can’t say, and that’s been incredibly valuable.
One of the more revealing moments for me came when we began evaluating how the agent performed with the A–Z directory. This is a resource that has long served as the backbone for finding services and offices across the university. But once we put the agent to work with this data, the limitations of that system became painfully clear. What we had assumed was structured, complete, and reliable turned out to be limited, outdated, and in some cases, misleading.
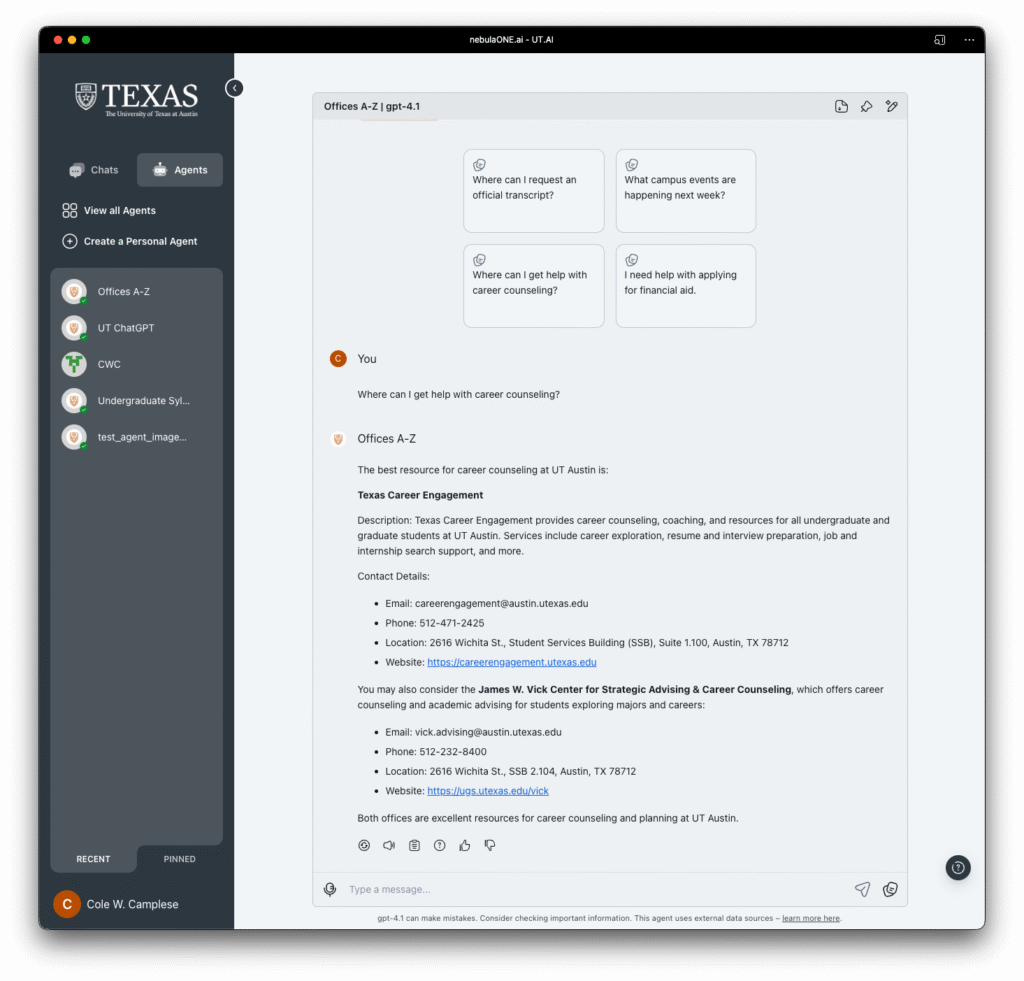
This has been a bit of a wake-up call. It is so tempting to take a “lift and shift” approach, move what we have on the web into the AI agent and assume it will just work. But that does not hold up. The agent exposes what the web often hides. It forces precision. It requires context. And it absolutely demands trust in the data that fuels it.
We are now integrating these insights into a more systematic approach. Each time a query breaks down, we want to trace it back. What we need to be asking centers on: Should this information exist? If so, where should it live? Can we make it easier to find, easier to understand, and easier for the agent to serve up confidently?
This work is not just about making our AI better. It’s about making our websites more accessible, our documentation more useful, and our services more responsive. Every gap we close improves the experience not just for the agent, but for the human trying to find their way. I didn’t expect this kind of feedback loop to emerge so quickly, but I’m glad it has. It reminds us to slow down, look closely, and be intentional, not just with how we build agents, but how we steward the information we share across this institution.