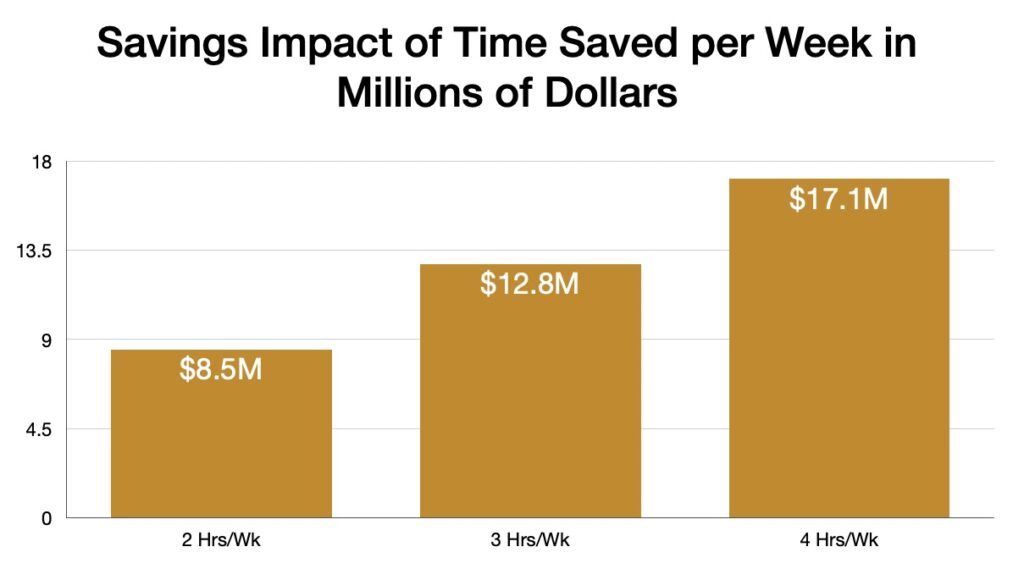
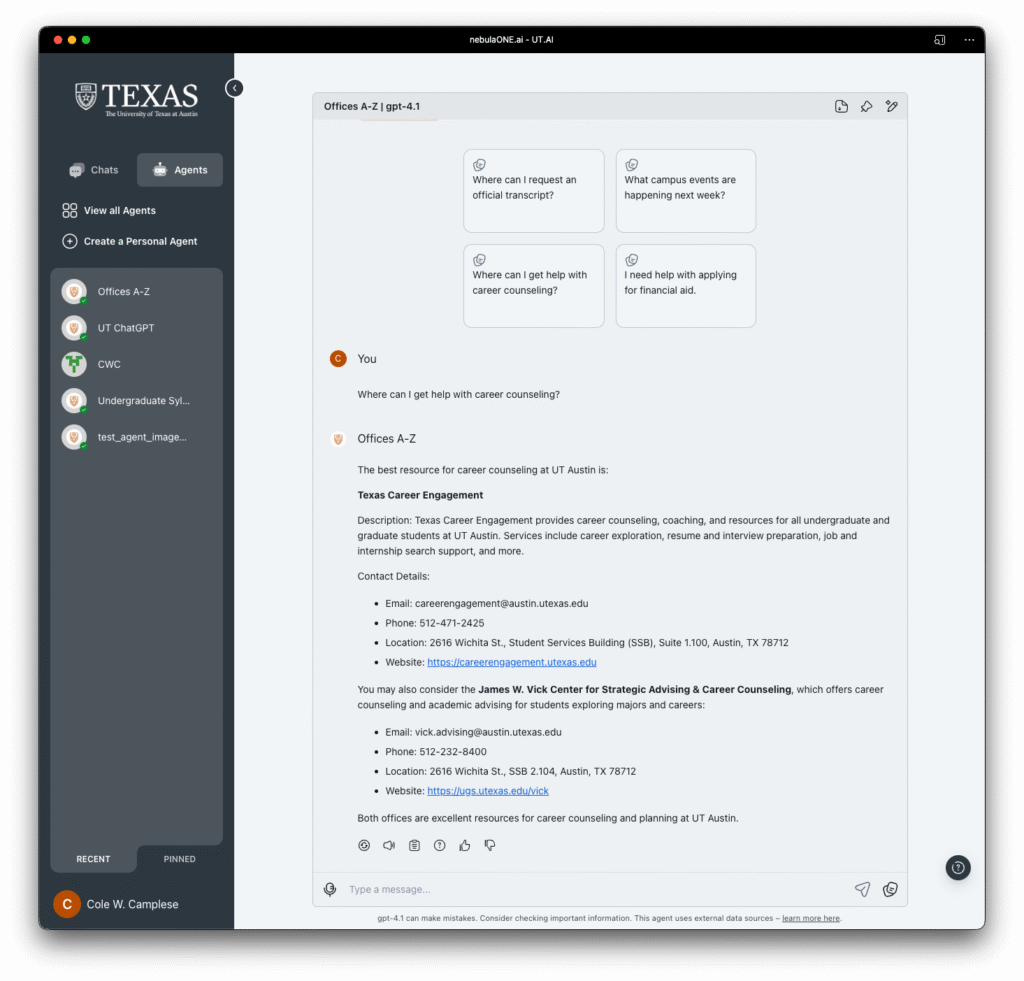
I was in a meeting with Microsoft executives this week talking about AI adoption, roadmaps, what comes next, the usual choreography of these conversations. And I found myself saying something I hadn’t planned to say: We are going to use AI to create a self-healing campus.
I want to try to explain what I meant because from what I am seeing emerge in the marketplace is nothing short of revolutionary. But I have to start somewhere that might seem like a detour: with a platform, and with institutional responsibility. Because the self-healing idea only works if the foundation is built right and building that foundation is the hardest part of the work.
Universities are complex institutions. We hold sensitive data about hundreds of thousands of people. We have federal compliance obligations, privacy commitments, accessibility requirements, and a duty to protect the identities and records of our students, faculty, and staff. Any vision of AI-powered self-service that ignores those realities isn’t innovation, it’s shadow IT with a new name. The history of higher education IT is full of well-intentioned workarounds that created breaches, compliance gaps, and technical debt of their own.
So before the self-healing can happen, someone has to build the environment that makes it safe. That is what we are doing at UT Austin with UT.AI.
UT.AI is our attempt to build a common AI environment where the institutional protections are not an afterthought — they are the foundation. Data protection, privacy, accessibility, security, and institutional identity are baked in from the start, so that everything built on top of it inherits those guarantees by default. The goal is not to restrict what the community can do with AI. It is to make it possible for them to do more, safely.
With that foundation established, here is the idea that excites me. Tools like Claude Code, GitHub Copilot, and OpenAI Codex are making it possible for people who are not professional software engineers to build working software. A procurement officer who understands the byzantine logic of a university purchasing workflow can now describe what they need and have a running application in an afternoon. A researcher who has spent twenty years building expertise in a domain can translate that expertise into automation without waiting for IT to prioritize their ticket. The knowledge that has always lived in people’s heads, contextual, accumulated, irreplaceable, can now be turned directly into tools.
This is significant. But it isn’t the part that struck me most. What if you don’t have to wait for an institution to build the interface you need? What if you just describe it — and it appears?
Here’s the thought that hit me: if I can open Claude Code and describe a web application and have it built in front of me, then I am one step away from a world where I experience the web entirely on my own terms. Not the interface someone else designed for me. Not the portal IT built three years ago that nobody has the budget to modernize. My interface. The one that surfaces exactly the information I need, in exactly the format I want, through a gateway I described in plain language.
Think about what that means for a university. We have decades of accumulated technical debt — systems built for a version of the institution that no longer exists, interfaces designed around assumptions about how people work that stopped being true years ago. Every year, IT organizations like mine make triage decisions about what gets modernized and what stays on life support. We do the best we can. But the backlog is real, and it grows faster than we can address it.
The traditional answer is more resources, better prioritization, smarter governance. All of that still matters. But agentic AI introduces a different answer: what if the community doesn’t need us to fix all the interfaces, because they can make their own?
A faculty member who needs the grants management system to present data in a specific way shouldn’t have to wait for a system modernization project. They should be able to describe what they want — “show me my pending awards grouped by sponsor, sorted by close date, exportable to a format my department administrator can actually use” — and have that view rendered for them, connected to the underlying data, without touching the legacy system at all. The underlying system doesn’t have to change. The interface layer becomes personal, ephemeral, generated on demand.
This is what I mean by self-healing. Not that the old systems get fixed. But that the community builds around them, over them, through them and in doing so, the debt stops mattering the way it used to. The pain point that drove the ticket to IT gets resolved by the person who felt it, in the moment they felt it, using tools that are already available.
The interface layer becomes personal, ephemeral, generated on demand. Technical debt stops mattering the way it used to.
But here is why the platform layer is not optional. Every one of those personal gateways needs to know who you are, what data you are authorized to see, and how that data can be used. It needs to meet accessibility standards so that the self-service future is actually available to everyone, not just the technically confident. It needs to enforce the same privacy and security guarantees that govern every other institutional system. Without a common platform that provides those things by default, “self-healing” becomes “self-inflicted harm at scale.”
UT.AI is our attempt to thread that needle. Build the platform first; with institutional identity, data protection, privacy, accessibility, and security as non-negotiables. Then open it up so that the community can build on top of it, around it, through it. The freedom is real, but it is freedom within a responsible envelope, not despite one.
At UT Austin, we are already investing in the tools and infrastructure that make this possible. Through a year of UT Spark we have learned that going alone at the platform layer isn’t enough, through the AI Studio we are launching this fall, through the agentic capabilities we are putting in front of our community. This concept forces us to shift in how we think about what IT is for.
We are not just in the business of building and maintaining systems. We are in the business of enabling people to do their best work safely, equitably, and in ways that hold up under scrutiny. If agentic AI means that more and more of that enabling happens through description rather than deployment, through personal gateways rather than institutional portals, then our job is to make sure the foundation is solid enough that the community can build on top of it without putting themselves or the institution at risk.
That is a campus that heals itself. And I think it is closer than it looks.