
Following up on Part 1 and Part 2, it is time to look at adding explicit prefetching to try to increase read bandwidth.
About Prefetching
The AMD Opteron Family10h processors have two different “hardware” prefetch mechanisms, and also allow “software” prefetch instructions. The “core prefetcher” is (as the name implies) located in the processor core, and monitors L1 Data Cache misses. (There is a similar prefetch engine for Instruction Cache misses, but that is not today’s topic.) This “core prefetcher” monitors a large number of data access streams and prefetches along detected address streams consisting of contiguous ascending or descending cache line addresses. I believe that the core prefetcher only fetches one cache line ahead of the most recent load to each stream, waiting until a cache line is returned from memory before sending out the next request, so it will not “automagically” create enough prefetches to fill the memory pipeline.
(Note that these sorts of details are hard to tease out of vendor documentation, and are subject to frequent change.) The core prefetcher is operational in all of the results presented here, with many of the code modifications intended to make it operate more effectively.
The Opteron Family10h processors also have a “Memory Controller Prefetcher” that prefetches from DRAM to special buffers in the memory controller. This can reduce the latency for subsequent memory accesses, and therefore increase the bandwidth available with a fixed level of concurrency. This part is really important, so I will repeat it:
Bandwidth = Concurrency / Latency
The concurrency is limited by the number of buffers available for outstanding cache misses (8 per core, in this case), while the latency is determined by where the data ends up getting found. In the system under test the latency is actually bounded below by the time required to probe the other caches in the system, not by the time required to obtain the data from the DRAMs. In the first generation of AMD Opteron Family10h processors (Revisions B0 & B3), the memory controller prefetcher simply read the data from the DRAMs to a set of buffers in the memory controller. In these systems the cache coherency check was not initiated until the processor actually sent a load for a particular cache line to the memory controller. Unfortunately in this case the time required to check the other caches to see if they had a copy of the line was considerably longer than the time required to get the data from the DRAM, so getting the data from the DRAM earlier did not help at all — it just meant that the processor had to wait longer after receiving the data before it could use it. In Revision C of the AMD Opteron Family10h processors, the memory controller prefetcher was enhanced to make “coherent” prefetches — the memory controller began the coherence transaction when it performed the prefetch. In the best case the coherence transaction will be complete by the time the load request from the processor arrives, which significantly reduces the latency observed by the processor. From the formula above, it should be clear that for a fixed level of concurrency, the only way to increase sustained bandwidth is to reduce the effective latency. In Revisions D and E of the AMD Opteron Family10h processors, this “coherent prefetcher” is retained with some additional improvements.
Finally we get to “Software Prefetch”. The AMD64/Intel64 instruction set includes a set of explicit prefetch instructions. There are two versions that matter, the “PREFETCH T0” instruction and the “PREFETCH NTA” instruction. The former fetches data from memory much like a load, while the latter fetches data from memory and marks it as “non-temporal” — meaning that it is unlikely to be reused. For Family10h Opterons “non-temporal” fetches go into the L1 cache but when they are chosen to be replaced in the L1 Cache, they are simply dropped (if clean) rather than being sent to the L2 Cache as “victims”. This allows the L2 Cache to be used more effectively for data that is likely to be reused. Since the array used in this benchmark is much larger than the cache, I could use the PREFETCH_NTA instruction when explicitly prefetching data. The choice of prefetch instruction does not make much difference in performance here, though it can sharply reduce performance if the code does end up reusing the data, so in these examples I use PREFETCH_T0 just as a habit.
Different revisions of hardware treat software prefetches differently — again it is hard to obtain this information from vendor documentation. There are several issues relating to software prefetch behavior that can influence how you want to use them:
- Do software prefetches cause access violations if the address is out-of-bounds?
No they do not. This makes them easier to use since you can prefetch beyond the end of an array without worrying about access violations. - Do software prefetches trigger the hardware page table walker in the event of a TLB miss?
Yes, on Family10h Opterons. This is usually a good thing, though there is only one hardware page table walker per core. The SW prefetch will only cause a hardware table walk — if the page table entry is not found by the hardware table walker, the request will be silently dropped. This is different than a load, which will cause a trap to O/S software if the page table entry is not found by the hardware table walker (for example if the page has been swapped to disk). - Do the addresses used in software prefetches trigger the hardware prefetchers like loads do?
In earlier Opterons I think that the answer was “no”, and in Family10h Opterons I think that the answer is “yes”, but it does not matter in this particular test case. - Do software prefetches combine in the cache miss buffers with load misses, or do they allocate separate buffers?
For AMD Family10h processors the Miss Address Buffers combine all accesses to the same cache line, whether due to hardware prefetches, load misses, or software prefetches. This makes it less critical that the code avoid issuing both load misses and SW prefetches to the same cache line.
Prefetching Experiments
I repeated most of the previous experiments with explicit software prefetch instructions added. In each case I varied the distance between the current loop pointer and the target of the prefetch from 0 8-Byte elements to 1024 8-byte elements. The prefetch instructions were added using yet another compiler intrinsic function executed once per loop (which explains why I prefer to unroll the inner loop to handle a cache line at a time). The inner loop of Version 003 (with 4 scalar variables as partial sums) then becomes Version004:
for (i=0; i<N; i+=8) {
_mm_prefetch((char *)&a[i+AHEAD],_MM_HINT_T0);
sum0 += a[i+0];
sum1 += a[i+1];
sum2 += a[i+2];
sum3 += a[i+3];
sum0 += a[i+4];
sum1 += a[i+5];
sum2 += a[i+6];
sum3 += a[i+7];
}
and the resulting assembly code for the inner loop is as expected:
..B1.10:
addsd a(%rdx), %xmm3
addsd 8+a(%rdx), %xmm2
addsd 16+a(%rdx), %xmm1
addsd 24+a(%rdx), %xmm0
addsd 32+a(%rdx), %xmm3
addsd 40+a(%rdx), %xmm2
addsd 48+a(%rdx), %xmm1
addsd 56+a(%rdx), %xmm0
prefetcht0 (%rax)
addq $64, %rax
addq $64, %rdx
addq $8, %rcx
cmpq $32768000, %rcx
jl ..B1.10
The performance of Version 004 is now dependent on the AHEAD distance, as shown in Figure 1.
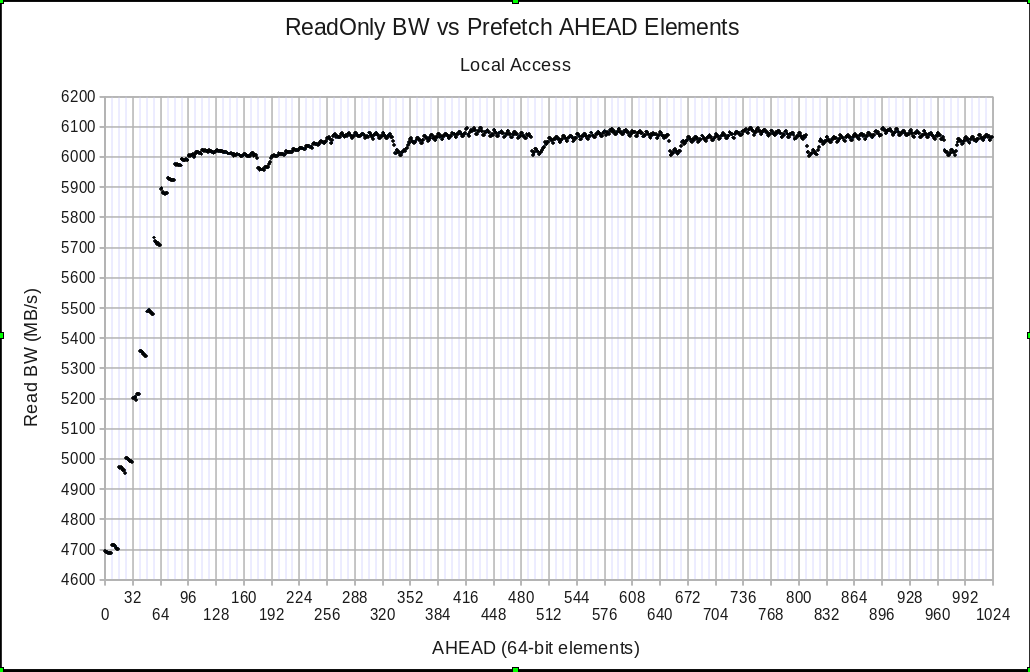
Single thread bandwidth (Version 004) as a function of the distance between the current pointer and the software prefetch address.
Comparing to Version 003, the explicit software prefetching increases the bandwidth dramatically, from ~4.5 GB/s to over 6.0 GB/s. Without trying to understand the details, it is clear that it helps a great deal to prefetch at least 96 elements ahead, with 96 elements = 768 Bytes = 12 cache lines. There are nice wide ranges that show steady levels of performance, with (for example) the average of AHEAD=416 to AHEAD=448 coming to 6.083 GB/s. Given the 74 ns nominal memory latency, this corresponds to an effective concurrency of 450 Bytes, or slightly over 7.0 cache lines. Note that this is approaching the maximum value that a single thread should be able to attain unless the memory controller prefetcher is able to significantly reduce the effective memory latency.
Combining the explicit software prefetching of Version 004 with the packed double SSE of Version 003 produces Version 005. Unfortunately the performance of Version 004 and Version 005 is essentially identical — the reduction in pipeline latency provided in Version 005 overlaps with the improvement in latency due to software prefetching, producing no additional gain.
Putting Data on Large Pages
The AMD Opteron Family10h processors support a standard virtual memory page size of 4 KiB with large pages sizes of 2 MiB and 1 GiB. Most versions of Linux support only one option for large page sizes, typically the 2 MiB version. I configured the system under test to reserve 512 large pages behind each chip and modified the benchmark to use these large pages. Some compilers (notably the Open64 compilers) have compile/link options to put the data on large pages, but I prefer doing it a bit more manually using shared memory segments. This has the advantage of portability across all compilers and can be switched back to the default page size by a simple change to the parameters to the shmget() call. One slightly tricky issue is that when using large pages the size requested in the shmget call needs to be rounded up to the nearest multiple of the page size. The code to allocate the array on large pages looks like:
i = total/(2*1024*1024); // how many full 2MiB pages in "total" bytes?
sum = ceil((double)total/(2.*1024.*1024.)); // round up to next integer if needed
j = (int) sum; // ceil() returns a double -- convert to integer
SEGSIZE = j*(2*1024*1024); // now the SEGSIZE is the smallest multiple of 2MiB needed to hold "total" bytes
shmida = shmget(IPC_PRIVATE,SEGSIZE,IPC_CREAT|SHM_HUGETLB|0666); // simply eliminate the SHM_HUGETLB to get the default page size
a = (double *) shmat (shmida, NULL, 0); // *real* code should check for error returns on both the shmget and shmat calls!
Taking the packed double SSE Version 006 and putting the data on large pages gives us Version 007. This version does not include software prefetching. Performance is improved slightly by the use of large pages, from 5.247 GB/s (Version 006) to 5.392 GB/s (Version 007) — a bit under 3% improvement. Not to worry — the main goal of using large pages is not to directly improve performance, but to allow control over which DRAM banks and ranks are being accessed.