
In the previous post, I published my best set of numbers for local memory latency on a variety of AMD Opteron system configurations. Here I expand that to include remote memory latency on some of the systems that I have available for testing.
Ranger is the oldest system still operational here at TACC. It was brought on-line in February 2008 and is currently scheduled to be decommissioned in early 2013. Each of the 3936 SunBlade X6420 nodes contains four AMD “Barcelona” quad-core Opteron processors (model 8356), running at a core frequency of 2.3 GHz and a NorthBridge frequency of 1.6 GHz. (The Opteron 8356 processor supports a higher NorthBridge frequency, but this requires a different motherboard with “split-plane” power supply support — not available on the SunBlade X6420.)
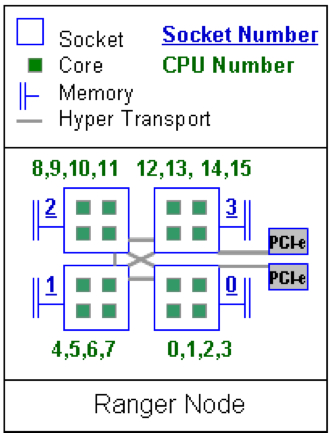
The on-node interconnect topology of the SunBlade X6420 is asymmetric, making maximum use of the three HyperTransport links on each Opteron processor while still allowing 2 HyperTransport links to be used for I/O.
As seen in the figure below, chips 1 & 2 on each node are directly connected to each of the other three chips, while chips 0 & 3 are only connected to two other chips — requiring two “hops” on the HyperTransport network to access the third remote chip. Memory latency on this system is bounded below by the time required to “snoop” the caches on the other chips. Chips 1 & 2 are directly connected to the other chips, so they get their snoop responses back more quickly and therefore have lower memory latency.
A variant of the “lat_mem_rd.c” program from “lmbench” (version 2) was used to measure the memory access latency. The benchmark chases a chain of pointers that have been set up with a fixed stride of 128 Bytes (so that the core hardware prefetchers are not activated) and with a total size that significantly exceeds the size of the 2MiB L3 cache. For the table below, array sizes of 32MiB to 1024MiB were used, with negligible variations in observed latency. For this particular system, the memory controller prefetchers were active with the stride of 128 used, but since the effective latency is limited by the snoop response time, there is no change to the effective latency even when the memory controller prefetchers fetch the data early. (I.e., the processors might get the data earlier due to memory controller prefetch, but they cannot use the data until all the snoop responses have been received.)
Memory latency for all combinations of (chip making request) and (chip holding data) are shown in the table below:
| Memory Latency (ns) | Data on Chip 0 | Data on Chip 1 | Data on Chip 2 | Data on Chip 3 |
|---|---|---|---|---|
| Request from Chip 0 | 133.2 | 136.9 | 136.4 | 145.4 |
| Request from Chip 1 | 140.3 | 100.3 | 122.8 | 139.3 |
| Request from Chip 2 | 140.4 | 122.2 | 100.4 | 139.3 |
| Request from Chip 3 | 146.4 | 137.4 | 137.4 | 134.9 |
