Last March I attended my first Kung FU AI advisory board meeting. I walked away feeling way out in front, we had contracts in place with Microsoft, OpenAI, and Anthropic for campus to safely consume the best of the emerging AI market. It was a classic “if you provide it, they will come” approach. Fast forward to March of 2026 and I walked away from the same annual meeting with a different feeling: that we have let the early momentum slide.
What I listened to as I sat and looked around the room were CTO, CEO, COO type people not talking about procurement wins or what they were thinking about AI, but instead about how they spent much of the year activating and enabling their IT organizations to be AI-first in their decision making. The intentional adoption of AI to drive impact was more important than early wins and “low hanging fruit.”
I left that meeting feeling a different kind of urgency, one that was aimed directly at enabling the teams that make up Enterprise Technology. One of the first things I did was schedule an all day retreat with the ET senior leadership team. Mario and I sat down and laid out the sketch of how we wanted to approach the SLT and built a framework that was meant to challenge each of us. The challenge was to come to a place where we would take a very intentional turn and focus on internal adoption, diffusion, and enablement.
That is a hard turn for an organization that spends nearly all of its time looking out across campus. We have rightly focused on campus adoption, diffusion, and enablement while often times leaving ourselves behind. What I learned from the advisory board meeting was that the only way to grow outside of ET is to first grow inside ET.
With that in mind we walked into our retreat and declared that that day was Day Zero of ET’s intentional AI adoption and enablement practice. We each made commitments. We also addressed the outcomes of our first ET AI Use Survey, where we learned that our staff were reluctant to adopt AI for reasons we hadn’t considered: environmental, ethical, and uneven tooling concerns dominated the results. It was an opportunity for us as the leadership team to square our organizational expectations and commit to focusing significant effort inside ET to enable success for all of campus.
Today we sent a strong message to the ET staff that they have the support and commitment from their leaders to bring us all into the world of AI to improve our own work, support campus, and to challenge ourselves to rise to this moment. My favorite part of the memo reads:
ET’s core values are not a backdrop to this work. They are the reason for it. We exist to advance the university’s digital ecosystem so the Longhorn community can learn, discover, and succeed. That mission requires us to develop our people, engage our campus partners, build an organization that is agile enough to act on new opportunities, measure our progress honestly, and enhance the technology environment for teaching, learning, and research. AI is the most consequential technology shift of our time. Sitting it out is not an option that is consistent with who we say we are.
In the coming weeks and months there will be lots of ongoing conversations, training, and events designed to enable our teams. We have AI Enablement workshops starting next week that will bring all of our teams up to a baseline with both OpenAI and Claude. We have made the SLT commitments available to every member of Enterprise Technology and we will deliver. We have another AI in a Day event planned that will allow our staff to hear directly from the audiences we serve across campus to spark ideas and new partnerships. And we will culminate this calendar year with an event designed to bring our AI champions together in an ET Build event that will focus on deepening our skills and using them to solve our own problems of practice.
All of this is designed to get us to a point where we can begin to work with our campus partners in new and exciting ways. This means understanding what the offices of the CFO, COO, Advancement, Student Affairs, Legal Affairs, and all the others struggle with — challenges that can be augmented by AI, agents, and workflows. The focus inward is intentional and we believe it will be the unlock we need to continue our AI leadership in higher education.
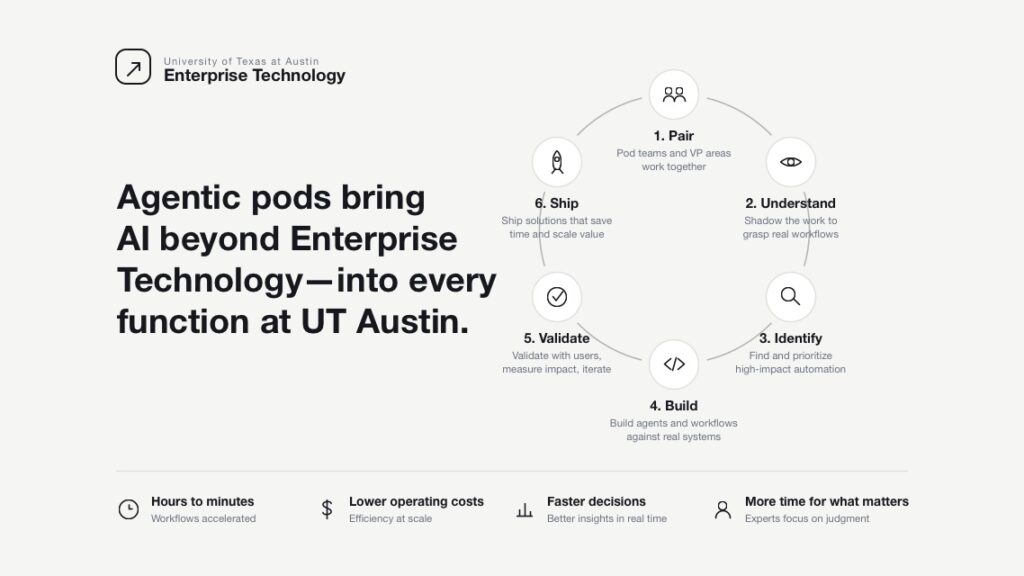
As our teams grow their skills in AI, we will pair with offices across campus to create “agentic pods” to move our enablement work to them. The method itself isn’t new; it is simply an evolution of the tooling and practices we are all familiar with. When the UT.AI Studio fully launches, we will be able to augment our teams with our AI Student Builders and further expand impact. I am grateful to be at a place that demands to be on the forefront of discovery and we get to be part of that journey in a very meaningful way.