
The primary metric for memory bandwidth in multicore processors is that maximum sustained performance when using many cores. For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
This post is about a secondary performance characteristic — sustained memory bandwidth for a single thread running on a single core. This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operating systems almost always process each call (e.g., buffer copies for filesystem access) with a single thread. In my own experience, I have found that systems with higher single-core bandwidth feel “snappier” when used for interactive work — editing, compiling, debugging, etc.
With that in mind, I decided to mine some historical data (and run a few new experiments) to see how single-thread/single-core memory bandwidth has evolved over the last 10-15 years. Some of the results were initially surprising, but were all consistent with the fundamental “physics” of bandwidth represented by Little’s Law (lots more on that below).
Looking at sustained single-core bandwidth for a kernel composed of 100% reads, the trends for a large set of high-end AMD and Intel processors are shown in the figure below:
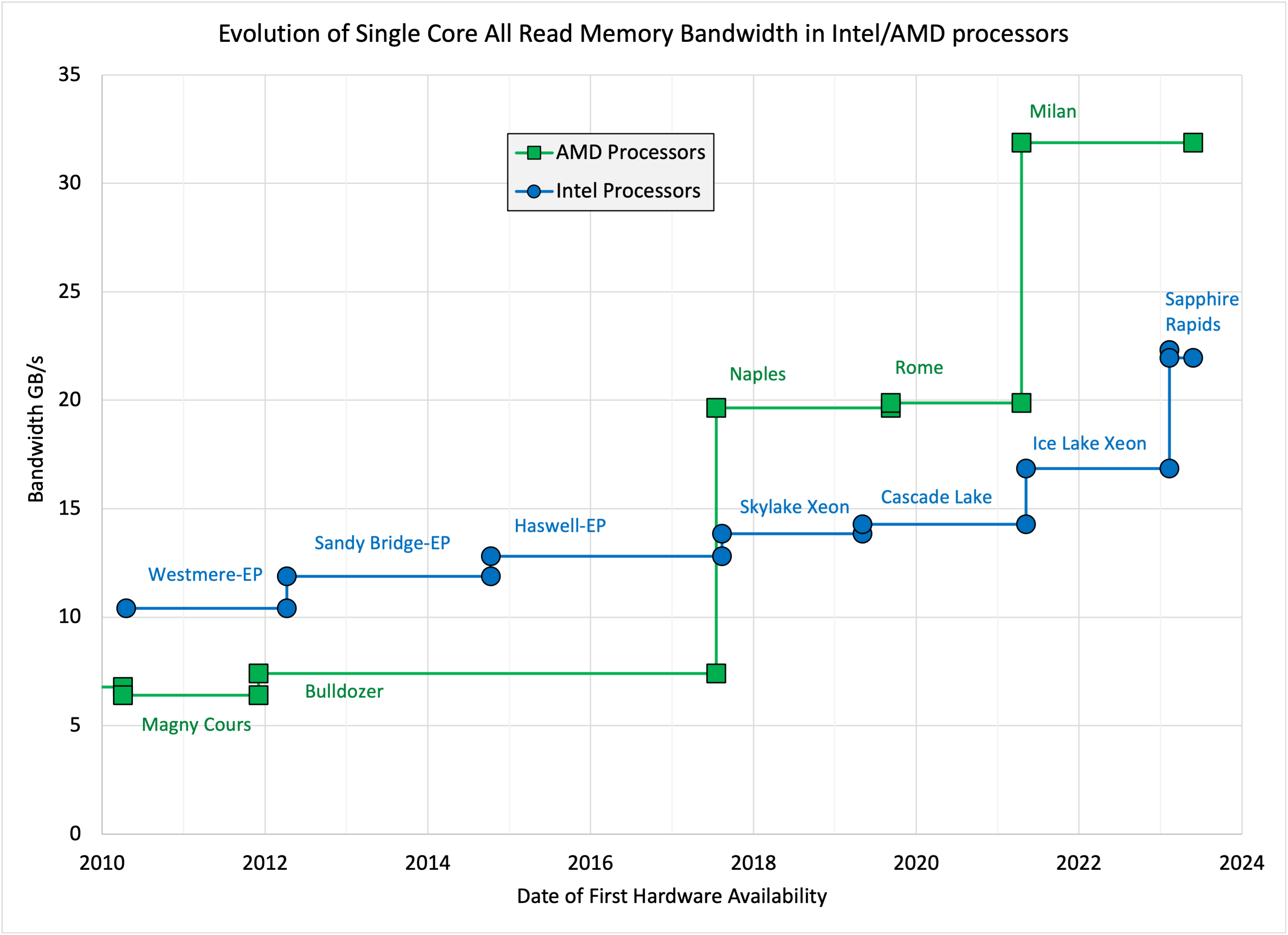
So from 2010 to 2023, the sustainable single-core bandwidth increased by about 2x on Intel processors and about 5x on AMD processors.
Are these “good” improvements? The table below may provide some perspective:
| 2023 vs 2010 speedup | 1-core BW | 1-core GFLOPS | all-core BW | all-core GFLOPS |
| Intel | ~2x | ~5x | ~10x/DDR5 ~30x/HBM | >40x |
| AMD | ~5x | ~5x | ~20x | ~30x |
The single-core bandwidth on the Intel systems is clearly continuing to fall behind the single-core compute capability, and a single core is able to exploit a smaller and smaller fraction of the bandwidth available to a socket. The single-core bandwidth on AMD systems is increasing at about the same rate as the single-core compute capability, but is also able to sustain a decreasing fraction of the bandwidth of the socket.
These observations naturally give rise to a variety of questions. Some I will address today, and some in the next blog entry.
Questions and Answers:
- Why use a “read-only” memory access pattern? Why not something like STREAM?
- I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog https://sites.utexas.edu/jdm4372/2010/11/)
- A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., https://sites.utexas.edu/jdm4372/2018/01/01/notes-on-non-temporal-aka-streaming-stores/)
- For the single-core case the bandwidth reported by the STREAM benchmark kernels is very close to the same as the bandwidth for the all-read tests reported here. (Details in the next blog entry.)
- Multicore processors have huge amounts of available DRAM bandwidth – maybe it does not even make sense for a single core to try to use that much?
- Any recent Intel processor core (Skylake Xeon or newer) has a peak cache bandwidth of (at least) two 64-Byte reads plus one 64-Byte write per cycle. At a single-core frequency of 3.0 GHz, this is a read BW of 384 GB/s – higher than the full socket bandwidth of 307.2 GBs with 8 channels of DDR5/4800 DRAM. I don’t expect all of that, but the core can clearly make use of more than 20 GB/s.
- Why is the single-core bandwidth increasing so slowly?
- To understand what is happening here, we need to understand the way memory bandwidth interacts with memory latency and the concurrency (parallelism) of memory accesses.
- That is the topic of the next blog entry. (“Real Soon Now”)
- Can this problem be fixed?
- Sure! We don’t need to violate any physical laws to increase single-core bandwidth — we just need the design support the very high levels of memory parallelism we need, and provide us with a way of generating that parallelism from application codes.
- The NEC Vector Engine processors provide a demonstration of very high single-core bandwidth. On a VE20B (8 cores, 1.6 GHz, 1530 GB/s peak BW from 6 HBM stacks), I see single-thread sustained memory bandwidth of 304 GB/s on the ReadOnly benchmark used here.
Stay tuned!